Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

В сегодняшнем райтапе мы с тобой проэксплуатируем прошлогоднюю уязвимость в Apport — системе сообщений о неполадках в Ubuntu. Но чтобы получить доступ к ней, сначала проведем атаку на Joomla, получим сессию на сервере и найдем учетные данные пользователя.
Все это — в рамках прохождения машины Devvortex с учебной площадки Hack The Box. Уровень сложности задания отмечен как легкий.
warning
Подключаться к машинам с HTB рекомендуется только через VPN. Не делай этого с компьютеров, где есть важные для тебя данные, так как ты окажешься в общей сети с другими участниками.
Добавляем IP-адрес машины в /etc/hosts:
10.10.11.242 devvortex.htb
И запускаем сканирование портов.
Справка: сканирование портов
Сканирование портов — стандартный первый шаг при любой атаке. Он позволяет атакующему узнать, какие службы на хосте принимают соединение. На основе этой информации выбирается следующий шаг к получению точки входа.
Наиболее известный инструмент для сканирования — это Nmap. Улучшить результаты его работы ты можешь при помощи следующего скрипта:
#!/bin/bashports=$(nmap -p- --min-rate=500 $1 | grep ^[0-9] | cut -d '/' -f 1 | tr 'n' ',' | sed s/,$//)nmap -p$ports -A $1
Он действует в два этапа. На первом производится обычное быстрое сканирование, на втором — более тщательное сканирование, с использованием имеющихся скриптов (опция -A).
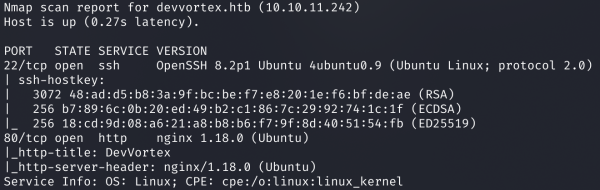
Результат работы скрипта
Сканер нашел два открытых порта:
Выбор небольшой, поэтому осмотрим веб‑сервер.
Главная страница сайта
На сайте ничего интересного найти не удалось, поэтому приступим к сканированию.
Справка: сканирование веба c feroxbuster
Одно из первых действий при тестировании безопасности веб‑приложения — это сканирование методом перебора каталогов, чтобы найти скрытую информацию и недоступные обычным посетителям функции. Для этого можно использовать программы вроде dirsearch, DIRB или ffuf. Я предпочитаю feroxbuster.
При запуске указываем следующие параметры:
-u — URL; -w — словарь (я использую словари из набора SecLists); -t — количество потоков; -d — глубина сканирования. Задаем все аргументы и запускаем feroxbuster:
feroxbuster -u http://devvortex.htb/ -t 128 -d 1 -w directory_2.3_medium_lowercase.txt
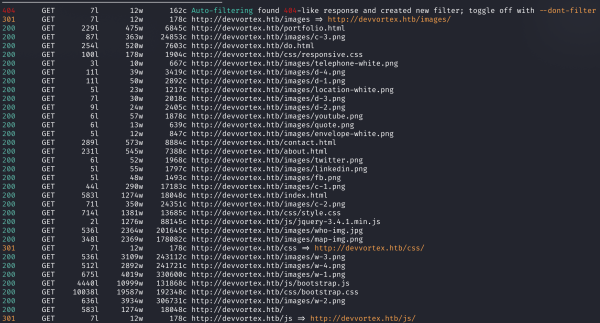
Результат сканирования каталогов с помощью feroxbuster
Опять же ничего интересного не получаем, поэтому сканируем поддомены. Для этого используем ffuf. Параметры следующие:
-u — URL; -w — словарь; -t — количество потоков; -H — HTTP-заголовок. ffuf -u "http://devvortex.htb/" -H 'Host: FUZZ.devvortex.htb' -t 128 -w subdomains-top1million-110000.txt
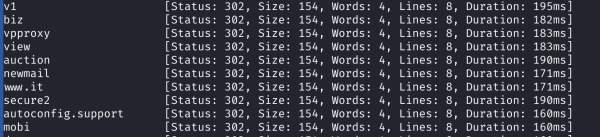
Результат сканирования поддоменов с помощью ffuf
Но в вывод приложения попадают все варианты из списка, поэтому нужно добавить фильтр по размеру страницы (параметр -fs):
ffuf -u "http://devvortex.htb/" -H 'Host: FUZZ.devvortex.htb' -t 128 -w subdomains-top1million-110000.txt -fs 154

Результат сканирования поддоменов с помощью ffuf
Мы нашли поддомен dev, а значит, обновляем запись в файле /etc/hosts:
10.10.11.242 devvortex.htb dev.devvortex.htb
И идем смотреть обнаруженный сайт.
Главная страница сайта
Но и здесь не нашлось ничего, что можно было бы использовать для развития атаки. Значит, нужно сканировать файлы и каталоги.
feroxbuster -u http://dev.devvortex.htb/ -t 128 -d 1 -w files_interesting.txt
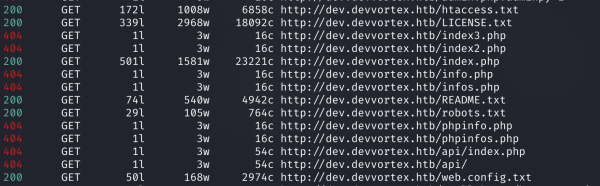
Результат сканирования каталогов с помощью feroxbuster
В выводе видим файл robots.txt.
Справка: robots.txt
Этот файл используется для того, чтобы попросить краулеры (например, Google, Яндекс и прочие) не трогать какие‑то определенные каталоги. Например, никто не хочет, чтобы в поисковой выдаче появлялись страницы авторизации администраторов сайта, файлы или персональная информация со страниц пользователей и прочие вещи в таком духе. Однако и злоумышленники первым делом просматривают этот файл, чтобы узнать о файлах и каталогах, которые хочет спрятать администратор сайта.
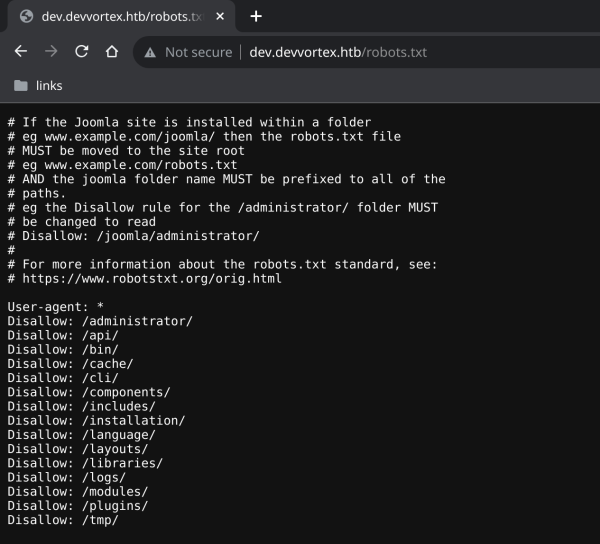
Содержимое файла robots.txt
Получаем интересные страницы, а также узнаём, что используется Joomla. А из файла README.txt узнаём и версию этой системы управления контентом.
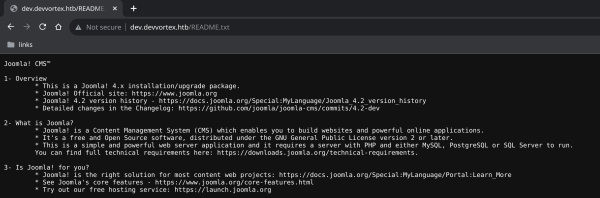
Содержимое файла README.txt
Первым делом стоит проверить, есть ли для обнаруженной CMS уже готовые эксплоиты. Самый надежный способ найти готовый эксплоит — поискать в интернете на сайтах вроде HackerOne, Exploit-DB, а также GitHub.
Поиск эксплоитов в Google
Источник: xakep.ru


