Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Создатели вредоносных программ используют массу разных методов, чтобы скрыть свои творения от антивирусных средств и статических-динамических анализаторов. Однако и антивирусы не лыком шиты: для поиска «родственных» семплов они используют продвинутые алгоритмы хеширования. Сегодня мы расскажем, как работают эти алгоритмы, — с подробностями и наглядными примерами.
На практике в большинстве случаев существующая база или ядро вредоноса повторно используется для создания новой разновидности малвари. Вирусописатели особо не заморачиваются с затратной по времени разработкой новых «качественных» вирусов, а просто используют имеющиеся образцы.
Этот повторно используемый код может быть собран заново с помощью другого компилятора, из него могут быть удалены или, наоборот, в него могут быть добавлены новые функции. Обновляются некоторые библиотеки, меняется распределение кода внутри файла (при этом применяются новые компоновщики, пакеры, обфускация и так далее). Смысл таких преобразований — придать хорошо знакомой антивирусу вредоносной программе новый вид. В этом случае видоизмененная версия вируса какое-то время останется необнаруженной. Тем не менее существуют способы детектирования такого рода переупаковок и модификаций.
Эти техники обнаружения зачастую используются для анализа большого массива данных и поиска в нем общих элементов. Практическими примерами использования похожих техник могут быть глобально распределенные базы знаний, такие как Virus Total и базы антивирусных компаний, а также подходы Threat Intelligence.
Ханс Петер Лун из IBM еще в 1940-е разрабатывал системы для анализа информации, в том числе исследовал вопросы хранения, передачи и поиска текстовых данных. Это привело его к созданию алгоритмов преобразования, а затем и к хешированию информации в качестве способа поиска телефонных номеров и текста. Так индексация и концепция «разделяй и властвуй» сделали свои первые шаги в области вычислительной техники.
Сейчас существует множество алгоритмов хеширования, отличающихся криптостойкостью, скоростью вычисления, разрядностью и другими характеристиками.
Мы привыкли ассоциировать хеш-функции с криптографическими хеш-функциями. Это распространенный инструмент, который используется для решения целого ряда задач, таких как:
В сегодняшней статье речь пойдет о том, как различные алгоритмы хеширования помогают нам бороться с зловредным ПО.
Криптографическая хеш-функция, чаще называемая просто хешем, — это математическое преобразование, переводящее произвольный входной массив данных в состоящую из букв и цифр строку фиксированной длины. Хеш считается криптостойким, если справедливо следующее:
MD5, SHA-1 и SHA-256 — наиболее популярные криптографические алгоритмы вычисления хеша, которые часто используются в детектировании вредоносного ПО. Еще совсем недавно вредонос опознавали только по сигнатуре (хешу) исполняемого файла.
Но в современных реалиях недостаточно знать просто хеш объекта, так как это слабый индикатор компрометации (IoC). IoC — это все артефакты, на основе которых может быть выявлен вредонос. Например, используемые им ветки реестра, подгружаемые библиотеки, IP-адреса, байтовые последовательности, версии ПО, триггеры даты и времени, задействованные порты, URL.
Рассмотрим «пирамиду боли» для атакующего, придуманную аналитиком в области информационной безопасности Дэвидом Бьянко. Она описывает уровни сложности индикаторов компрометации, которые злоумышленники используют при атаках. Например, если ты знаешь MD5-хеш вредоносного файла, его можно довольно легко и при этом точно обнаружить в системе. Однако это принесет очень мало боли атакующему — достаточно добавить один бит информации к файлу вредоноса, и хеш изменится. Таким образом вирус может переселяться бесконечно, и каждая новая его копия будет иметь отличный от других экземпляров хеш.
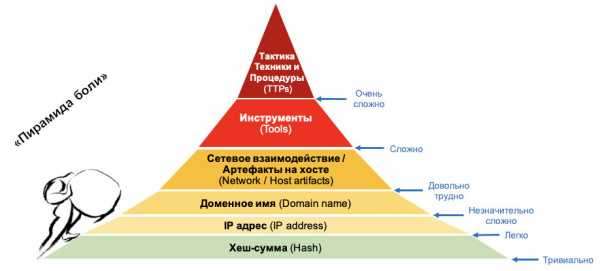
«Пирамида боли» Дэвида Бьянко
Если ты имеешь дело с множеством вредоносных образцов, становится понятно, что большинство из них по сути своей не уникальны. Злоумышленники нередко заимствуют или покупают исходники друг у друга и используют их в своих программах. Очень часто после появления в паблике исходных кодов какого-либо вредоносного ПО в интернете всплывают многочисленные поделки, состряпанные из доступных фрагментов.
Как же определить схожесть между разными образцами малвари одного семейства?
Для поиска такого сходства существуют специальные алгоритмы подсчета хеша, например нечеткое (fuzzy) хеширование и хеш импортируемых библиотек (imphash). Эти два подхода используют разные методы обнаружения для поиска повторно встречающихся фрагментов вредоносных программ, принадлежащих к определенным семействам. Рассмотрим эти два метода подробнее.
Если в криптографических хеш-функциях суть алгоритма состоит в том, что при малейшем изменении входных данных (даже одного бита информации) их хеш также значительно изменяется, то в нечетких хешах результат меняется незначительно или не изменяется вовсе. То есть нечеткие хеши более устойчивы к небольшим изменениям в файле. Поэтому подобные функции позволяют намного более эффективно обнаруживать новые модификации вредоносного ПО и не требуют больших ресурсов для расчета.
Нечеткое хеширование — это метод, при котором программа, такая как, например, SSDeep, вычисляет кусочные хеши от входных данных, то есть использует так называемое контекстно вызываемое кусочное хеширование. В англоязычных источниках этот метод называется context triggered piecewise hashing (CTPH aka fuzzy hashing).
На самом деле классификаций нечетких хешей довольно много. Например, по механизму работы алгоритмы делятся на piecewise hashing, context triggered piecewise hashing, statistically improbable features, block-based rebuilding. По типу обрабатываемой информации их можно разделить на побайтовые, синтаксические и семантические. Но если речь заходит о нечетких хешах, то это, как правило, CTPH.
Алгоритм SSDeep разработан Джесси Корнблюмом для использования в компьютерной криминалистике и основан на алгоритме spamsum. SSDeep вычисляет несколько традиционных криптографических хешей фиксированного размера для отдельных сегментов файла и тем самым позволяет обнаруживать похожие объекты. В алгоритме SSDeep используется механизм скользящего окна rolling hash. Его еще можно назвать рекурсивным кусочным хешированием.
Часто CTPH-подобные хеши лежат в основе алгоритмов локально чувствительных хешей — locality-sensitive hashing (LSH). В их задачи входит поиск ближайших соседей — approximate nearest neighbor (ANN), или, проще говоря, похожих объектов, но с чуть более высокоуровневой абстракцией. Алгоритмы LSH используются не только в борьбе с вредоносным ПО, но и в мультимедиа, при поиске дубликатов, поиске схожих генов в биологии и много где еще.
Как работает SSDeep? На первый взгляд, все довольно просто:
Virus Total использует SSDeep, который выполняет нечеткое хеширование на загружаемых пользователями файлах. Пример — по ссылке.
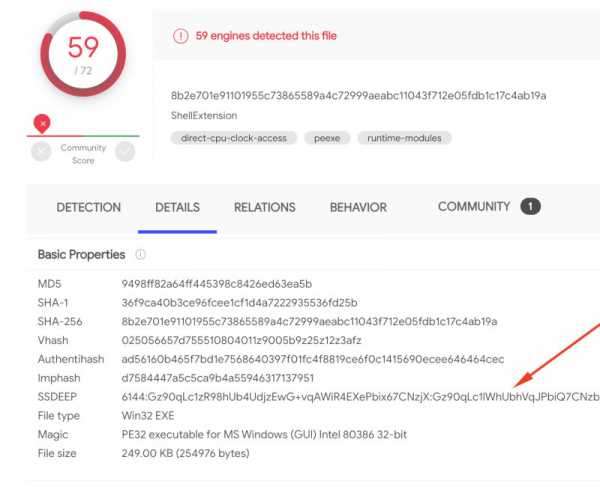
Virus Total использует SSDeep
Источник: xakep.ru


