Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


Раньше капча с числами была отличным способом отсеять ботов, а сейчас такая разновидность уже почти не встречается. Думаю, ты и сам догадываешься, в чем дело: нейросети научились распознавать такие капчи лучше нас. В этой статье мы посмотрим, как работает нейронная сеть и как использовать Keras и Tensorflow, чтобы реализовать распознавание цифр.
Для каждого примера я приведу код на Python 3.7, который ты можешь запустить, чтобы посмотреть, как все это работает. Для запуска примеров потребуется библиотека Tensorflow. Установить ее можно командой pip install tensorflow-gpu, если видеокарта поддерживает CUDA, в противном случае используй команду pip install tensorflow. Вычисления с CUDA в несколько раз быстрее, так что, если твоя видеокарта их поддерживает, это сэкономит немало времени. И не забудь установить наборы данных для обучения сети командой pip install tensorflow-datasets.
Все приведенные в этой статье примеры работают полностью автономно. Это важно, потому что существуют различные онлайн-сервисы AI, например компании Amazon, которые берут оплату за каждый запрос. Создав и обучив собственную нейронную сеть с помощью Python и Tensorflow, ты сможешь использовать ее неограниченно и независимо от какого-либо провайдера.
Как работает один нейрон? Сигналы со входов (1) суммируются (2), причем каждый вход имеет свой «коэффициент передачи» — w. Затем к получившемуся результату применяется «функция активации» (3).
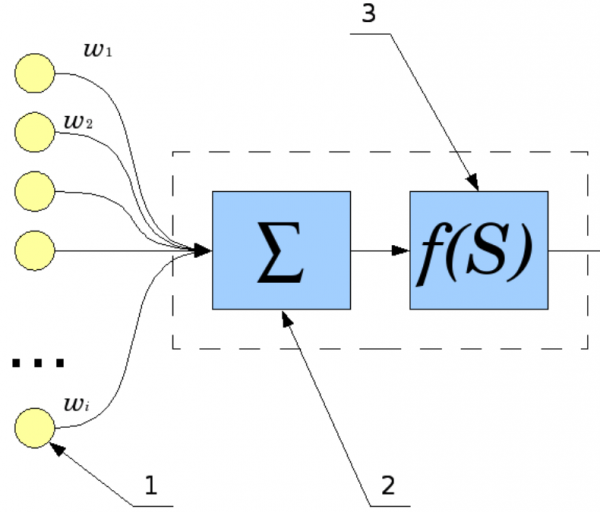
Модель нейрона
Типы этой функции различны, она может быть:
Еще в 1943 году Мак-Каллок и Питтс доказали, что сеть из нейронов может выполнять различные операции. Но сначала эту сеть нужно обучить — настроить коэффициенты w каждого нейрона так, чтобы сигнал передавался нужным нам способом. Запрограммировать нейронную сеть и обучить ее с нуля сложно, но, к счастью для нас, все необходимые библиотеки уже написаны. Благодаря компактности языка Python все действия можно запрограммировать в несколько строк кода.
Рассмотрим простейшую нейросеть и научим ее выполнять функцию XOR. Разумеется, вычисление XOR с помощью нейронной сети не имеет практического смысла. Но именно оно поможет нам понять базовые принципы обучения и использования нейросети и позволит по шагам проследить ее работу. С сетями большей размерности это было бы слишком сложно и громоздко.
Сначала нужно подключить необходимые библиотеки, в нашем случае это tensorflow. Я также отключаю вывод отладочных сообщений и работу с GPU, они нам не пригодятся. Для работы с массивами нам понадобится библиотека numpy.
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
import tensorflow_datasets as tfds # pip install tensorflow-datasets
import tensorflow as tf
import logging
import numpy as np
tf.logging.set_verbosity(tf.logging.ERROR)
tf.get_logger().setLevel(logging.ERROR)
Теперь мы готовы создать нейросеть. Благодаря Tensorflow на это понадобится всего лишь четыре строчки кода.
model = Sequential()
model.add(Dense(2, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
Мы создали модель нейронной сети — класс Sequential — и добавили в нее два слоя: входной и выходной. Такая сеть называется «многослойный перцептрон» (multilayer perceptron), в общем виде она выглядит так.
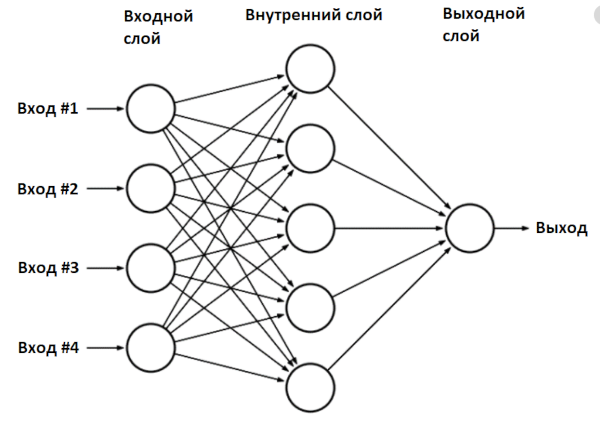
Сеть multilayer perceptron
В нашем случае сеть имеет два входа (внешний слой), два нейрона во внутреннем слое и один выход.
Можно посмотреть, что у нас получилось:
print(model.summary())
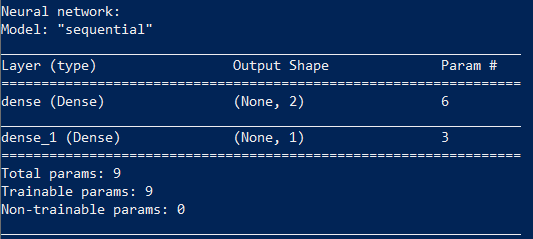
Параметры сети
Обучение нейросети состоит в нахождении значений параметров этой сети.
Наша сеть имеет девять параметров. Чтобы обучить ее, нам понадобится исходный набор данных, в нашем случае это результаты работы функции XOR.
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([[0], [1], [1], [0]])
model.fit(X, y, batch_size=1, epochs=1000, verbose=0)
Функция fit запускает алгоритм обучения, которое у нас будет выполняться тысячу раз, на каждой итерации параметры сети будут корректироваться. Наша сеть небольшая, так что обучение пройдет быстро. После обучения сетью уже можно пользоваться:
print("Network test:")
print("XOR(0,0):", model.predict_proba(np.array([[0, 0]])))
print("XOR(0,1):", model.predict_proba(np.array([[0, 1]])))
print("XOR(1,0):", model.predict_proba(np.array([[1, 0]])))
print("XOR(1,1):", model.predict_proba(np.array([[1, 1]])))
Результат соответствует тому, чему сеть обучалась.
Network test:
XOR(0,0): [[0.00741202]]
XOR(0,1): [[0.99845064]]
XOR(1,0): [[0.9984376]]
XOR(1,1): [[0.00741202]]
Мы можем вывести все значения найденных коэффициентов на экран.
## Parameters layer 1
W1 = model.get_weights()[0]
b1 = model.get_weights()[1]
## Parameters layer 2
W2 = model.get_weights()[2]
b2 = model.get_weights()[3]
print("W1:", W1)
print("b1:", b1)
print("W2:", W2)
print("b2:", b2)
print()
Результат:
W1: [[ 2.8668058 -2.904025 ] [-2.871452 2.9036295]]
b1: [-0.00128211 -0.00191825]
W2: [[3.9633768] [3.9168582]]
b2: [-4.897212]
Внутренняя реализация функции model.predict_proba выглядит примерно так:
x_in = [0, 1]
## Input
X1 = np.array([x_in], "float32")
## First layer calculation
L1 = np.dot(X1, W1) + b1
## Relu activation function: y = max(0, x)
X2 = np.maximum(L1, 0)
## Second layer calculation
L2 = np.dot(X2, W2) + b2
## Sigmoid
output = 1 / (1 + np.exp(-L2))
Рассмотрим ситуацию, когда на вход сети подали значения [0,1]:
L1 = X1*W1 + b1 = [0*2.8668058 + 1*-2.871452 + -0.0012821, 0*-2.904025 + 1*2.9036295 + -0.00191825] = [-2.8727343 2.9017112]
Функция активации ReLu (rectified linear unit) — это просто замена отрицательных элементов нулем.
X2 = np.maximum(L1, 0) = [0. 2.9017112]
Теперь найденные значения попадают на второй слой.
L2 = X2*W2 + b2 = 0*3.9633768 +2.9017112*3.9633768 + -4.897212 = 6.468379
Наконец, в качестве выхода используется функция Sigmoid, которая приводит значения к диапазону 0…1:
output = 1 / (1 + np.exp(-L2)) = 0.99845064
Мы совершили обычные операции умножения и сложения матриц и получили ответ: XOR(0,1) = 1.
С этим примером на Python советую поэкспериментировать самостоятельно. Например, ты можешь менять число нейронов во внутреннем слое. Два нейрона, как в нашем случае, — это самый минимум, чтобы сеть работала.
Но алгоритм обучения, который используется в Keras, не идеален: нейросети не всегда удается обучиться за 1000 итераций, и результаты не всегда верны. Так, Keras инициализирует начальные значения случайными величинами, и при каждом запуске результат может отличаться. В моем случае сеть с двумя нейронами успешно обучалась лишь в 20% случаев. Неправильная работа сети выглядит примерно так:
XOR(0,0): [[0.66549516]]
XOR(0,1): [[0.66549516]]
XOR(1,0): [[0.66549516]]
XOR(1,1): [[0.00174837]]
Но это не страшно. Если видишь, что нейронная сеть во время обучения не выдает правильных результатов, алгоритм обучения можно запустить еще раз. Правильно обученную сеть потом можно использовать без ограничений.
Можно сделать сеть поумнее: использовать четыре нейрона вместо двух, для этого достаточно заменить строчку кода model.add(Dense(2, input_dim=2, activation='relu')) на model.add(Dense(4, input_dim=2, activation='relu')). Такая сеть обучается уже в 60% случаев, а сеть из шести нейронов обучается с первого раза с вероятностью 90%.
Все параметры нейронной сети полностью определяются коэффициентами. Обучив сеть, можно записать параметры сети на диск, а потом использовать уже готовую обученную сеть. Этим мы будем активно пользоваться.
Источник: xakep.ru


