Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124



Это рассказ о том, как я сделал декомпилятор вроде Hex-Rays для экзотического языка программирования, используемого для скриптов игры «Мор (Утопия)». Ты узнаешь, как работает кросс‑компиляция, и получишь необходимый теоретический минимум из теории компиляции, который поможет тебе сделать так же. info
Полный код моих скриптов и результат работы декомпилятора ищи на GitHub.
Мы будем работать с ассемблерным кодом, полученным в статье «Мод (Утопия)». Он представляет собой набор из 89 опкодов. Фактически у нас есть только набор команд и заголовки файла.
Декомпиляция на язык более высокого уровня на самом деле является кросс‑компиляцией. То есть мы пишем компилятор, который принимает на вход исходный код на одном языке и превращает его в код на другом. Для этого мы создадим граф исполнения оригинального кода и напишем простенький эмулятор для стековой машины. Но обо всем по порядку. В написании декомпилятора мне сильно помог опыт работы с Angr, о котором я тоже уже писал статью. Фактически я повторил типовые решения, используемые в компиляторах и анализаторах кода, и это сработало! Спасибо теории компиляции.
Первый шаг анализа любого кода — разбить его на базовые блоки, то есть набор инструкций, который обрывается командой передачи управления. Затем из базовых блоков можно построить граф, отразив связи: кто и кому передает управление.
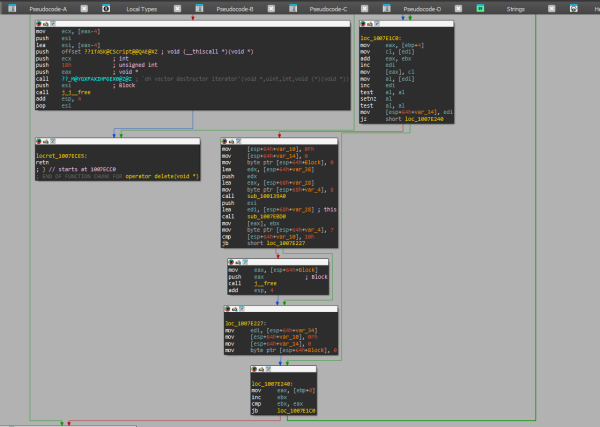
Знакомый многим граф в IDA Pro
Из картинки видно, что есть блоки, которые кончаются командами, не передающими управление. Это связано с тем, что следующий за ними участок кода используется как адреса перехода. То есть другой код (обычно цикл) передает управление в середину базового блока. В таком случае блок делится на два так, чтобы второй начинался с адреса, на который могут передать управление.
Поэтому первым делом я прохожу по всему коду и запоминаю адреса переходов. Будь это команда CALL или JMP — записываем, куда они передают управление. После этого можно делить код на базовые блоки. Проходим от первой инструкции до последней, разделяя их по известным адресам перехода. Для этого я ввел специальные поля в классе самой инструкции: метаданные, хранящие адреса и тип перехода — условный или безусловный.
Разделив код на базовые блоки (создав массив объектов BasicNode), можно приступать к их связыванию, то есть установке ссылок — на какой блок передает управление исследуемый. Каждый базовый блок содержит информацию о своем адресе (адресе первой входящей в него инструкции) и об адресах перехода, которые известны последней инструкции.
Граф должен иметь вершину — первую инструкцию, с которой начинается поток управления. Заголовки из ассемблерного файла дают список возможных точек входа. Я запускаю рекурсивный анализ от первого базового блока, после чего алгоритм проходит по всем адресам перехода и добавляет к блоку ссылки на «дочерние».
При этом каждый блок я прохожу лишь единожды. Существует глобальный список seen — адреса блоков, которые алгоритм уже видел. При повторном анализе они будут проигнорированы. Это позволяет быстро анализировать рекурсивный граф, в котором могут быть вложенные циклы.
Когда все ссылки на «дочерние» блоки расставлены, граф готов. Это аналог абстрактного синтаксического древа (AST). Дальше мы будем работать только с ним.
Проприетарный язык игры поддерживает аналог команд CALL и RET из обычного ассемблера x86. Однако тут нет никаких соглашений о вызовах вроде stdcall. Установить число переменных, передаваемых как аргументы функции, невозможно без полноценной эмуляции местного стека.
Поэтому я не стал выделять начала функций как отдельные вершины графа. Каждый вызов значится как обычная передача управления, а тело вызываемой функции — часть тела вызывающей. Этот трюк позволяет анализировать функцию в контексте вызывающего ее кода. После первичного анализа функцию можно выделить в отдельный граф.
Я решил показать все этапы анализа на примере небольшого файла fire.bin. Вот как выглядит его ассемблерный код:
RunOp = 0x6 RunTask = 1 GlobalTasks: GTASK_0 Params = 0 EVENT_5 Op = 0x3 Vars = () GTASK_1 Params = 0 EVENT_6 Op = 0x26 Vars = () 0x0: @ Hold() 0x1: Pop(0) 0x2: Return(); Pop(0) 0x3: @ StopGroup0() 0x4: Pop(0) 0x5: Return(); Pop(0) 0x6: PushEmpty(object, object) 0x7: PushEmpty(bool) 0x8: Call 0x2c 0x9: Pop(0) 0xa: Pop(1); Push((bool) Stack[-1] == 0) 0xb: IF (Stack[-1] == 0) GOTO 0x11; Pop(1) 0xc: PushEmpty() 0xd: Push(-0, 0); TaskCall(0) 0xe: Call 0x0 0xf: Pop(-0, 0); TaskReturn 0x10: Pop(0) 0x11: Push("fire") 0x12: @ FindParticleSystem(Stack[-1], Stack[-2]) 0x13: Pop(1) 0x14: Pop(0); Push((bool) Stack[-1] == 0) 0x15: IF (Stack[-1] == 0) GOTO 0x1a; Pop(1) 0x16: Push("Can't find fire particle system") 0x17: @ Trace(Stack[-1]) 0x18: Pop(1) 0x19: Return(); Pop(2) 0x1a: Push(CVector(0.0, 0.0, 0.0)) 0x1b: Push(CVector(0.0, 1.0, 0.0)) 0x1c: Push((float)0.0) 0x1d: @@ AddSource(Stack[-3], Stack[-2], Stack[-1]) 0x1e: Pop(3) 0x1f: @@ Enable() 0x20: Pop(0) 0x21: @ Hold() 0x22: Pop(0) 0x23: GOTO 0x21 0x24: Return(); Pop(2) 0x25: Stack[-1] = 0 0x26: PushEmpty() 0x27: Push(-0, 0); TaskCall(0) 0x28: Call 0x0 0x29: Pop(-0, 0); TaskReturn 0x2a: Pop(0) 0x2b: Return(); Pop(0) 0x2c: PushEmpty(bool, bool) 0x2d: @ IsLoaded(Stack[-1]) 0x2e: Pop(0) 0x2f: Stack[-3] = Stack[-1] 0x30: Return(); Pop(2)
Из заголовков видно, что тут есть три точки входа: 0x3, 0x6 и 0x26. Пройдя по коду, замечаем два адреса, на которые передается управление через Call, — 0x0 и 0x2C. Это вершины функций. Так выглядит первичный граф:
0x3: @ StopGroup0()0x4: Pop(0)0x5: Return(); Pop(0)0x26: PushEmpty()0x27: Push(-0, 0); TaskCall(0)0x28: Call 0x0 0x0: @ Hold() 0x1: Pop(0) 0x2: Return(); Pop(0) 0x29: Pop(-0, 0); TaskReturn 0x2a: Pop(0) 0x2b: Return(); Pop(0)0x6: PushEmpty(object, object)0x7: PushEmpty(bool)0x8: Call 0x2c 0x2c: PushEmpty(bool, bool) 0x2d: @ IsLoaded(Stack[-1]) 0x2e: Pop(0) 0x2f: Stack[-3] = Stack[-1] 0x30: Return(); Pop(2) 0x9: Pop(0) 0xa: Pop(1); Push((bool) Stack[-1] == 0) 0xb: IF (Stack[-1] == 0) GOTO 0x11; Pop(1) 0xc: PushEmpty() 0xd: Push(-0, 0); TaskCall(0) 0xe: Call 0x0 0x0: @ Hold() 0x1: Pop(0) 0x2: Return(); Pop(0) 0xf: Pop(-0, 0); TaskReturn 0x10: Pop(0) 0x11: Push("fire") 0x12: @ FindParticleSystem(Stack[-1], Stack[-2]) 0x13: Pop(1) 0x14: Pop(0); Push((bool) Stack[-1] == 0) 0x15: IF (Stack[-1] == 0) GOTO 0x1a; Pop(1) 0x16: Push("Can't find fire particle system") 0x17: @ Trace(Stack[-1]) 0x18: Pop(1) 0x19: Return(); Pop(2) 0x1a: Push(CVector(0.0, 0.0, 0.0)) 0x1b: Push(CVector(0.0, 1.0, 0.0)) 0x1c: Push((float)0.0) 0x1d: @@ AddSource(Stack[-3], Stack[-2], Stack[-1]) 0x1e: Pop(3) 0x1f: @@ Enable() 0x20: Pop(0) 0x21: @ Hold() 0x22: Pop(0) 0x23: GOTO 0x21
Для каждой точки входа граф строится отдельно, то есть их тут три штуки. Отступ слева обозначает начало дочернего блока.
У блока по адресу 0x26 есть два «ребенка»: вызов функции по адресу 0x0 и следующая по номеру инструкция 0x29. В первоначальном графе тело вызываемой функции прикреплено к «родительскому» блоку, но только один раз на граф.
Блок по адресу 0x9 содержит два дочерних блока: следующий по номеру 0xc и переход на 0x11. Из‑за этого перехода блок (внутри которого нет команд передачи управления) по адресу 0xf делится на два. При этом блок по адресу 0x11 одновременно является «ребенком» для блока 0xf, как следующий за ним по номеру. Но так как мы придерживаемся правила «не заходить в один блок дважды», граф будет отображаться с таким причудливым порядком вложенности.
Основная проблема декомпилированного кода — относительные адреса в стеке. К переменной обращаются через индекс от конца стека, и добавление новой переменной в конец стека ломает старые ссылки. Единственный способ понять, какая переменная где используется, — пройти по графу исполнения, симулируя все операции над стеком.
Для этого мне пришлось улучшить декомпилятор ассемблерного кода: я добавил каждой инструкции информацию о том, сколько переменных она достает из стека и какого типа переменные в стек помещает.
class CInstructionPop: def __init__(self, r): self.OpCode = 'Pop' self.VarIn = r.uint32() self.PopCount = self.VarIn def __repr__(self): return f'Pop({self.VarIn})'class CInstructionAdd: def __init__(self, r): self.OpCode = 'Add' self.Var1 = r.uint32() self.Var2 = r.uint32() self.TaskVar = r.int8() # signed self.PopCount = self.TaskVar & 0x3F self.PushType = [VAR_TYPE.INT] def __repr__(self): if self.TaskVar >= 0: var_1 = f'Stack[-{self.Var1}]' else: var_1 = f'Stack[{self.Var1} + StackPtr]' if self.TaskVar & 0x40: var_2 = f'Stack[{self.Var2} + StackPtr]' else: var_2 = f'Stack[-{self.Var2}]' return f'Pop({self.PopCount}); Push({var_1} + {var_2});'
Симулятор стека идет от вершины графа. Каждая инструкция добавляет или убирает из стека значения. Хитрость в том, что мы делаем два снимка стека для каждой инструкции — до выполнения опкода и после. И добавляем их как метаданные в тело инструкции. На следующем этапе анализа снимки стека помогут определить, какая переменная используется в инструкции.
0x6: PushEmpty(object, object)>before: []>after: [var_0_object, var_1_object] 0x7: PushEmpty(bool)>before: [var_0_object, var_1_object] >after: [var_0_object, var_1_object, var_2_bool]
Например, в самом начале функции 0x6 стек пустой, но первая команда помещает в него две переменные типа object. Следующая инструкция добавляет переменную типа bool.
Симулятор стека помнит номер последней созданной переменной и при помещении в стек новой выдает ей следующий порядковый номер. Простое решение с глобальным счетчиком оказалось чрезвычайно плодотворным. Каждая используемая переменная получила уникальный номер, а значит, ее использование можно отслеживать!
Источник: xakep.ru