Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

В израильской NSO Group создали эксплоит для iMessage, наделавший много шума. С помощью этого эксплоита троян Pegasus был внедрен в телефоны публичных деятелей и политиков. Apple уже подала иск на NSO. Однако оставим в стороне политику — в этой статье мы сосредоточимся на самом эксплоите, тем более что он просто взрывной! Заражает девайсы без участия юзера, укрывается внутри GIF и включает в себя крошечный виртуальный компьютер.
Начало тому, о чем мы будем говорить, было положено в августе 2016 года, когда израильская компания NSO Group, специализирующаяся на кибероружии, разработала и выпустила шпионское ПО Pegasus, предназначенное для заражения мобильных устройств под управлением Android и iOS. «Пегас» был способен читать текстовые сообщения, отслеживать звонки и местоположение, собирать пароли, получать информацию с микрофона и камеры, а также доступ к личной информации пользователя.
Тот старый «Пегас» 2016 года использовал эксплоит «одного нажатия» (one-click). То есть, когда пользователь‑жертва получал на свой смартфон «заряженное» сообщение, чтобы активировать подложенный сюрприз, ему нужно было что‑то сделать, например кликнуть по ссылке. Заражения было легко избежать — достаточно было не нажимать на что попало.
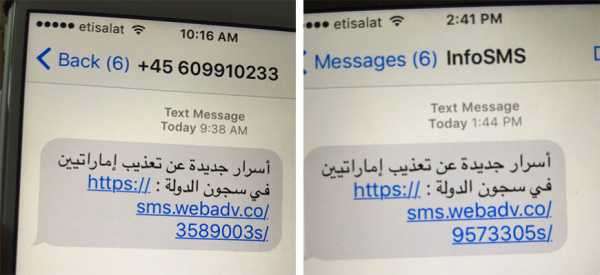
Примеры фишинговых СМС
В июле 2021 года исследователям из лаборатории Citizen Lab при Университете Торонто удалось изучить эксплоит «нулевого нажатия» для iMessage, обнаруженный на смартфоне активиста из Саудовской Аравии. Эксплоит работал вообще без участия пользователя и срабатывал сам — хакеру достаточно лишь отправить полезную нагрузку в мессенджере.
Входная точка «Пегаса» в iPhone — приложение iMessage. Это значит, что атакующему достаточно знать телефонный номер или Apple ID жертвы.
В iMessage есть нативная поддержка GIF-анимации. Присланная в чат гифка воспроизводится в цикле бесконечно. Как только iMessage получает сообщение, еще до его вывода на экран вызывается метод в процессе IMTranscoderAgent. Он, в свою очередь, выполняется за пределами песочницы BlastDoor. При этом в параметре метода передается любое изображение с расширением gif. Вот таким образом:
[IMGIFUtils copyGifFromPath:toDestinationPath:error]
Это пример кода на языке Objective-C. Посмотри на селектор. Здесь, вероятно, было намерение просто скопировать файл GIF перед редактированием поля счетчика циклов, но семантика этого метода иная. Внутри он использует API CoreGraphics, чтобы отобразить исходное изображение в новый GIF-файл по заданному пути. Однако то, что файл имеет расширение gif, вовсе не означает, что он на самом деле гифка.
Библиотека ImageIO применяется, чтобы опознать формат файла и проанализировать его, но при этом полностью игнорирует его расширение. При использовании этого трюка с «поддельными гифками» более 20 графических кодеков становятся потенциальными жертвами для атаки нулевого нажатия в iMessage. Некоторые из них очень сложны и состоят из сотен тысяч строк кода. Огромное пространство для хакерской смекалки!
Как сообщает исследовательская группа Google Project Zero, с iOS 14.8.1 (26 октября 2021 года) Apple ограничила форматы в ImageIO, доступные из процесса IMTranscoderAgent. Также инженеры компании полностью удалили код для доступа к GIF из IMTranscoderAgent с версии iOS 15.0 (20 сентября 2021 года), вместе с тем полностью перенеся декодирование GIF внутрь BlastDoor.
В NSO использовали дыру «поддельный GIF», чтобы через нее заюзать уязвимость в парсере CoreGraphics PDF.
Долгие годы формат PDF был излюбленной целью для атак — он доступен везде и обладает достаточной сложностью. Приятный бонус для хакеров — поддержка JavaScript внутри PDF. CoreGraphics PDF не интерпретирует JavaScript, тем не менее NSO удалось найти в недрах парсера кое‑что не менее мощное.
Иан Бир (Ian Beer) и Сэмюэл Гросс (Samuel Groß) из Project Zero распотрошили эксплоит NSO и подробно рассказали, как он работает. Дальше мы проследим за их исследованием, чтобы разобраться, как картинка превратилась в настоящий компьютер и помогла эксплоиту сбежать из песочницы.
В конце девяностых мало у кого был стабильный и быстрый интернет, большинство юзеров дозванивались к провайдеру по dial-up и работали на смешных сейчас скоростях. Да и диски не отличались большими емкостями, поэтому сжатие данных было важной технологией. PNG, JPEG и GIF нам знакомы и по сей день, но были и другие.
Формат JBIG2 предназначался для сжатия монохромных изображений (где пиксели могут быть только черными или белыми). Он применялся в офисных сканерах высокой ценовой категории, таких как Xerox WorkCenter.

Xerox WorkCenter
Если лет десять‑двадцать тому назад тебе доводилось использовать функцию «сканирования в PDF» на подобном устройстве, в получавшихся у тебя PDF, скорее всего, был поток JBIG2.
Примечательно, что эти файлы даже при достойном разрешении сканирования занимали всего несколько килобайтов. JBIG2 использует два метода для достижения такого мощного сжатия. Сейчас мы их обсудим. Только не думай, что мы тут отвлеклись на какую‑то побочную ерунду, — все это имеет непосредственное отношение к эксплуатации дыры в iMessage!
Текстовый документ, особенно написанный на языках с небольшими алфавитами (английский или, к примеру, русский), состоит из множества часто встречающихся символов. Вместе буквы, диакритику, знаки препинания и прочие загогулины называют глифами.
JBIG2 пытается сегментировать каждую страницу на глифы, а затем использует простое сопоставление с образцом, чтобы выделить глифы, которые выглядят одинаково.

Сопоставление с образцом позволяет найти все формы, в данном случае все буквы e
При этом JBIG2 ничего не знает о самих глифах и не пытается распознавать их и сопоставлять с алфавитом (OCR). Кодировщик JBIG2 просто ищет связанные области пикселей и группирует похожие.
При этом алгоритм сжатия заменяет все достаточно похожие на вид области копией только одной из них.

Замена всех вхождений одной копией глифа позволяет достичь высоких коэффициентов сжатия
В таком случае текст по‑прежнему прекрасно читается, однако объем хранимой информации становится меньше. Вместо того чтобы хранить данные о пикселях всей страницы, для их отображения нужна только сжатая версия «ссылочного глифа» для каждого символа и относительные координаты мест, где должны быть размещены его копии. При распаковке алгоритм расставляет глифы по местам, как бы рисуя ими на холсте.
Такой подход таит в себе существенный недостаток: кривой кодировщик может случайно спутать похожие на вид символы. А это приводит к печальным последствиям. В своем блоге Дэвид Кризель (David Kriesel) приводит несколько вдохновляющих примеров, когда в PDF-файлах сканированных счетов‑фактур и чертежей одни цифры меняются на другие. Для нас в данном случае эти проблемы не важны — разве что ими можно объяснить почти полное вымирание JBIG2.
Итак, результат сжатия на основе подстановки отображается с потерями. То есть после сжатия и распаковки вывод на вид не будет в точности соответствовать вводу. Поэтому JBIG2 поддерживает и сжатие без потерь, в которое входит промежуточный этап «сжатия с меньшими потерями».
В этом случае дополнительно используется информация о разнице между замещенным глифом и исходным — тоже, конечно же, сжатая. Вот пример, показывающий различия между замещенным символом слева и исходным символом без потерь посередине.
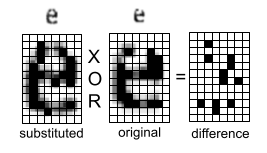
Использование оператора XOR на растрах для вычисления маски разности изображения
В примере выше кодировщик сохраняет маску разности, показанную справа, затем во время распаковки она подвергается операции XOR с замененным символом, чтобы восстановить точные пиксели, составляющие исходный символ.
Вместо того чтобы полностью кодировать всю разность за один раз, это можно сделать поэтапно, при этом на каждой итерации используется логический оператор (один из AND, OR, XOR или XNOR) для установки, сброса или переключения битов.
Каждый последующий шаг уточнения приближает конечный результат к оригиналу, и это позволяет контролировать потери качества при сжатии. Реализация этих шагов уточняющего кодирования очень гибкая. А еще здесь есть возможность читать значения, уже присутствующие в рабочей области вывода. А это, как ты уже, возможно, догадываешься, ведет нас к полноте по Тьюрингу… Но сначала нужно поговорить про важную уязвимость.
Большая часть декодера CoreGraphics PDF — это проприетарный код Apple, но реализация JBIG2 взята из проекта Xpdf, исходный код которого находится в свободном доступе.
Формат JBIG2 представляет собой набор сегментов, который можно рассматривать как серию команд рисования — они выполняются последовательно за один проход. Анализатор CoreGraphics JBIG2 поддерживает 19 различных типов сегментов, которые включают такие операции, как определение новой страницы, декодирование таблицы Хаффмана и визуализация растрового изображения с заданными координатами.
Сегменты представлены классом JBIG2Segment и его подклассами JBIG2Bitmap и JBIG2SymbolDict. JBIG2Bitmap представляет собой прямоугольный массив пикселей. Его поле данных указывает на задний буфер, содержащий поверхность для рендеринга. JBIG2SymbolDict группирует битмапы. А целевая страница представлена как JBIG2Bitmap и состоит из отдельных глифов. На сегменты (JBIG2Segment) можно ссылаться по номеру, а векторный тип GList хранит указатели на все сегменты. Чтобы найти сегмент по его номеру, GList сканируется последовательно.
Кстати, если ты сейчас прочитал слово «джи‑лист» неправильно и развеселился, как детсадовец, то постарайся сконцентрироваться, нас ждут куда более интересные открытия.
Источник: xakep.ru