Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Сегодня мы с тобой попентестим веб‑сервер на Windows: научимся манипулировать DNS, организуем утечку хеша NTLM, получим учетные данные управляемых записей AD и проэксплуатируем ограниченное делегирование Kerberos, чтобы повысить привилегии. Это позволит нам пройти машину Intelligence с площадки Hack The Box.
warning
Подключаться к машинам с HTB рекомендуется только через VPN. Не делай этого с компьютеров, где есть важные для тебя данные, так как ты окажешься в общей сети с другими участниками.
Добавляем IP-адрес машины в /etc/hosts:
10.10.10.248 intelligence.htb
И запускаем сканирование портов.
Справка: сканирование портов
Сканирование портов — стандартный первый шаг при любой атаке. Он позволяет атакующему узнать, какие службы на хосте принимают соединение. На основе этой информации выбирается следующий шаг к получению точки входа.
Наиболее известный инструмент для сканирования — это Nmap. Улучшить результаты его работы ты можешь при помощи следующего скрипта.
#!/bin/bashports=$(nmap -p- --min-rate=500 $1 | grep ^[0-9] | cut -d '/' -f 1 | tr 'n' ',' | sed s/,$//)nmap -p$ports -A $1
Он действует в два этапа. На первом производится обычное быстрое сканирование, на втором — более тщательное сканирование, с использованием имеющихся скриптов (опция -A).
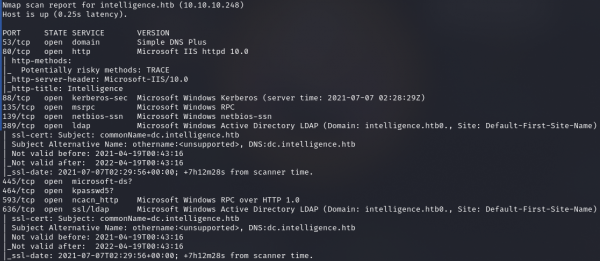
Результат работы скрипта
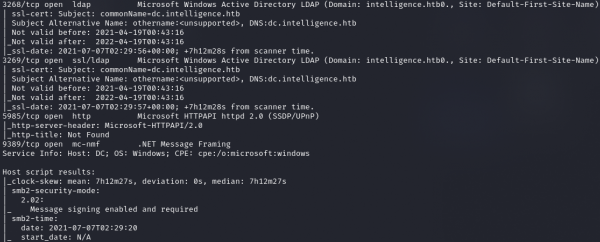
Результат работы скрипта (продолжение)
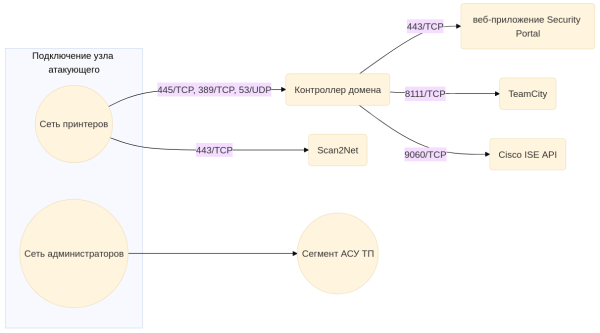
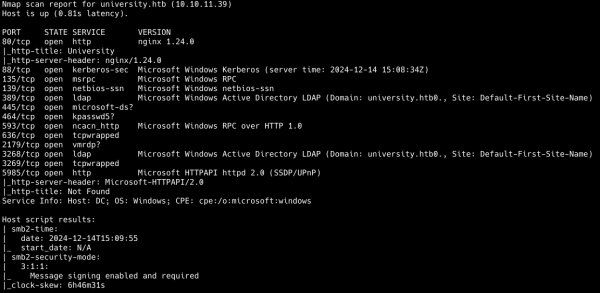
Видим множество открытых портов, что для Windows вполне характерно:
Еще в сертификате LDAP находим новое доменное имя dc.intelligence.htb, поэтому обновим запись в файле /etc/hosts:
10.10.10.248 intelligence.htb dc.intelligence.htb
Первым делом запустим скрипты Nmap для получения информации с DNS (nmap -p53 --script=dns* intelligence.htb), но из этого ничего не вышло. Авторизоваться как аноним в SMB и LDAP не получилось. Поэтому нам нужно пробивать веб.
Внимательно осмотримся на сайте и поищем ценную инфу. Сам сайт на первый взгляд кажется простеньким. Из интересного — на первой странице находим два PDF-документа.
Стартовая страница сайта
В документах ничего важного не обнаружилось. Но из любого курса по OSINT (разведка на основе открытых источников) ты узнаешь, что в документах самое интересное — это метаданные, особенно атрибуты вроде «создатель» или «владелец». Они могут раскрывать имена пользователей, которые потом можно использовать для доступа к учеткам.
Для получения метаинформации можно использовать exiftool. Чтобы установить и использовать ее, пишем:
sudo apt install exiftool
exiftool *
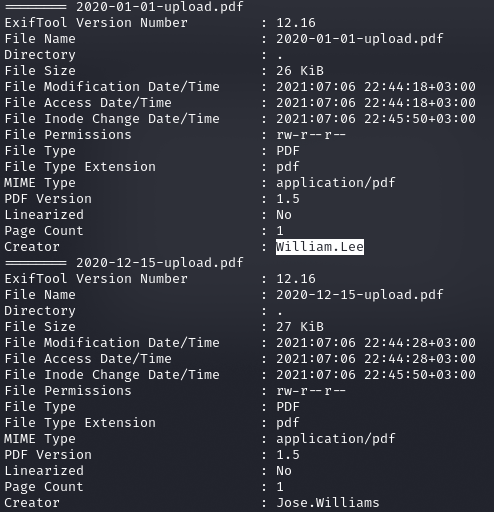
Получение метаинформации из документов
Мы нашли два имени, а значит, можем поискать аккаунты через аутентификацию Kerberos. Дело в том, что Kerberos нам сообщит, если пользователя нет в базе. Нужно лишь сформировать все возможные названия аккаунтов и просеивать их. К примеру, для пары name surname можно составить такие имена:
Administrator
Guest
name
namesurname
name.surname
names
name.s
sname
s.name
surname
surnamename
surname.name
surnamen
surname.n
nsurname
n.surname
Чтобы составлять юзернеймы по такому шаблону, используем следующий скрипт на Python:
#!/usr/bin/python3names = ["Jose Williams", "William Lee"]list = ["Administrator", "Guest"]for name in names: n1, n2 = name.split(' ') for x in [ n1, n1 + n2, n1 + "." + n2, n1 + n2[0], n1 + "." + n2[0], n2[0] + n1, n2[0] + "." + n1, n2, n2 + n1, n2 + "." + n1, n2 + n1[0], n2 + "." + n1[0], n1[0] + n2, n1[0] + "." + n2 ]: list.append(x)for n in list: print(n)
А теперь используем kerbrute для перебора имен. Указываем опцию перечисления пользователей и передаем их список.
./kerbrute_linux_amd64 userenum --dc intelligence.htb -d intelligence.htb namelist.txt
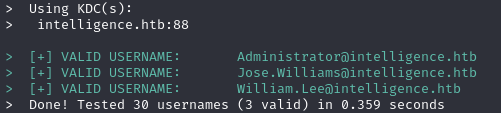
Найденные пользователи
Имена пользователей, указанные в документах, и оказались названиями аккаунтов. Дальше, что бы я ни попробовал (даже брут паролей), никуда продвинуться не вышло. Видимо, что‑то упустили на сайте.
Возвращаемся к вебу, на этот раз вооружившись Burp Suite. Благодаря Burp Proxy обращаем внимание на место хранения файлов и их названия.

Вкладка Burp Proxy
Имена файлов — это даты, а значит, мы можем попытаться найти и другие документы. Для этого отправляем запрос в Burp Intruder, чтобы перебрать и номер месяца, и день.
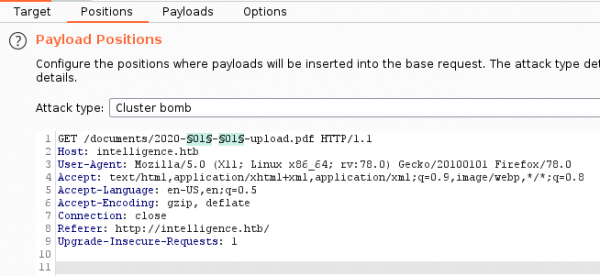
Burp Intruder — вкладка Position
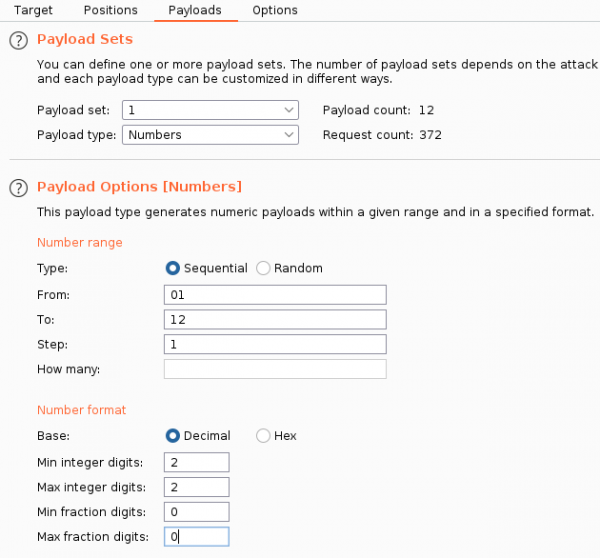
Burp Intruder — вкладка Payload (payload 1)
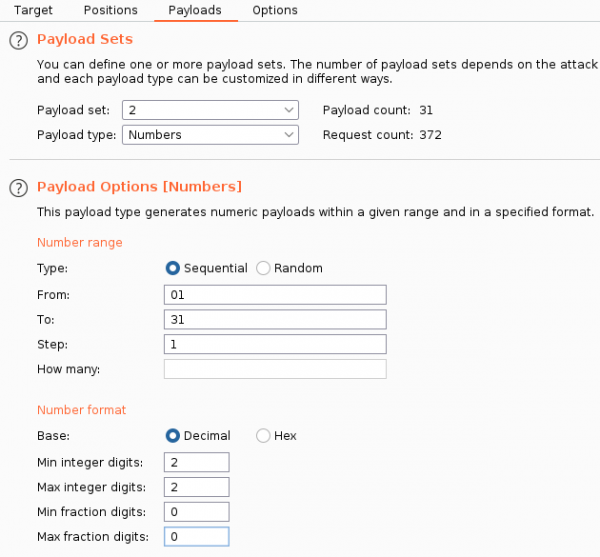
Burp Intruder — вкладка Payload (payload 2)
Сортируем результат по коду ответа, чтобы найти документы среди сообщений об ошибках.
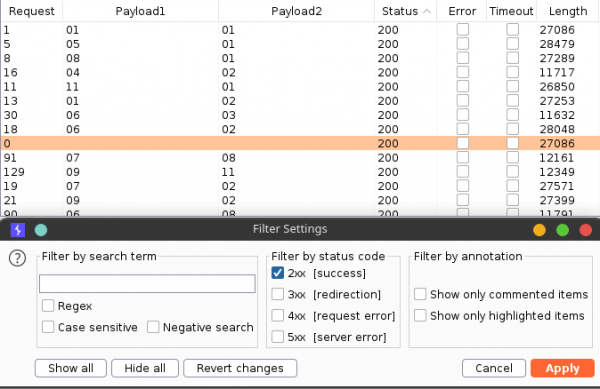
Результат атаки
Осталось их скачать. Сначала сохраним нужные нам нагрузки средствами Burp. Для этого отметим в фильтре, что нас интересует только код ответа 200, а затем выбираем Save → Results table.
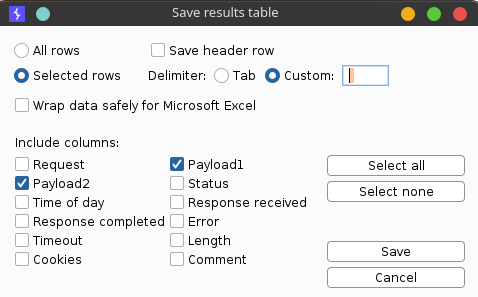
Сохранение нагрузок в файл
Поставим в качестве разделителя пробел и выберем только две нагрузки. Я сохранил нагрузки в файл save.txt, а потом скачал все эти документы через wget.
Источник: xakep.ru