Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Сегодня мы пройдем машину средней сложности с площадки Hack The Box. По дороге ты научишься получать и создавать данные в базе DynamoDB, посмотришь на работу с бакетами Amazon S3 и научишься получать данные через вложение в PDF, используя уязвимость в конвертере PDF4ML.
warning
Подключаться к машинам с HTB рекомендуется только через VPN. Не делай этого с компьютеров, где есть важные для тебя данные, так как ты окажешься в общей сети с другими участниками.
Первым делом я заношу IP машины (10.10.10.212) в файл /etc/hosts и даю ей более удобный адрес bucket.htb.
Затем переходим к сканированию портов. Я запускаю скрипт, который уже не раз описывал, и сканирую порты в два прохода (второй раз — со скриптами по найденным в первый раз портам).
#!/bin/bashports=$(nmap -p- --min-rate=500 $1 | grep ^[0-9] | cut -d '/' -f 1 | tr 'n' ',' | sed s/,$//)nmap -p$ports -A $1
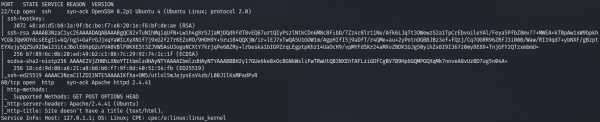
Результат работы скрипта
По результатам имеем два открытых порта: 22-й (служба SSH) и 80-й (веб‑сервер Apache). На SSH пока стучаться рано, поскольку у нас нет учетных данных. Гораздо перспективнее будет изучить веб‑сервер. Внимательно осмотримся на сайте, так как, помимо точек входа и разных уязвимостей, следует собирать и другую важную информацию, например имена пользователей, применяемые технологии и прочие вещи, которые могут пригодиться в дальнейшем. Сам сайт на первый взгляд кажется простеньким, и на первой же странице отметим доменное имя bucket.htb (с которым мы и так уже работаем), а также аккаунт техподдержки [email protected].
Главная страница сайта http://bucket.htb
Заглядываем в исходный код страницы и видим примечательную особенность — использованы теги для вставки изображений. Файлы с картинками загружаются с другого домена — s3.bucket.htb.
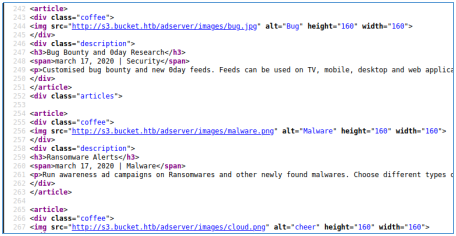
Исходный код домашней страницы http://bucket.htb
Значит, на веб‑сервере есть виртуальный хост s3.bucket.htb и, если мы хотим с ним работать, надо добавить и его в файл /etc/hosts. Сразу же можем проверить, что там.

Тестовый запрос по обнаруженному адресу
Вместо HTML с него возвращается статус выполнения, а значит, используется какая‑то служебная технология (из названия поддомена пока что стараемся не делать быстрых выводов).
Одно из первых действий при тестировании веб‑приложений — это сканирование сайта на наличие интересных каталогов и файлов. Особенно это полезно, когда натыкаешься на тупик, подобный тому, в котором мы оказались. Для сканирования можно применять широко известные программы dirsearch и DIRB, но я обычно пользуюсь более быстрым gobuster. При запуске используем следующие параметры:
dir — сканирование директорий и файлов;-t [] — количество потоков;-u [] — URL-адрес для сканирования;-w [] — словарь для перебора;--timeout [] — время ожидания ответа.gobuster dir -t 128 -u http://s3.bucket.htb -w /usr/share/wordlists/dirbuster/directory-list-lowercase-2.3-medium.txt --timeout 30s

Найденные каталоги на http://s3.bucket.htb/
Находим всего два интересных каталога. При обращении к первому снова получим ответ со статусом. Кстати, чтобы копаться в JSON, можно прямо в терминале использовать утилиту jq, передавая ей ответ на запрос.
curl http://s3.bucket.htb/health | jq
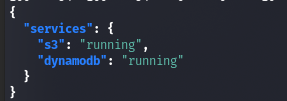
Преобразованный с помощью jq ответ от http://s3.bucket.htb/health
Обращаясь к каталогу shell, получим редирект на другой адрес:
http://444af250749d:4566/shell/
Если открыть его в браузере, можно увидеть, что это Amazon S3. Что ж, теперь никаких сомнений!
Страница, полученная при обращении к http://s3.bucket.htb/shell
Amazon Simple Storage Service (или S3) — это сервис для хранения объектов, полезный, когда нужно легко масштабирующееся хранилище. Его часто применяют, чтобы хранить статическую часть сайтов, ресурсы мобильных приложений, а также для хранения бэкапов и прочих подобных нужд. Также у Amazon есть своя СУБД класса NoSQL, которая хранит данные в формате «ключ — значение», она называется DynamoDB.
Наша цель — получить доступ к хранимым данным, поскольку они явно важны для прохождения машины. По S3 есть официальная документация. Ознакомившись с ней, ставим набор утилит AWS Command Line и настраиваем доступ к хранилищу.
sudo apt install awscli
aws configure

Конфигурация AWS CLI
Разберемся с заданными параметрами.
jq удобно читать JSON, выбираем его.Теперь, когда заданы основные параметры для работы с AWS, мы можем выполнять запросы к базе DynamoDB. Как и при работе с любой базой, первым делом просмотрим, есть ли доступные таблицы. В запросе используем следующие параметры:
dynamodb — указываем в качестве службы DynamoDB;list-table — для получения списка таблиц;--endpoint-url — URL для доступа к S3;--no-sign-request — не подписывать запрос.aws dynamodb list-tables --endpoint-url http://s3.bucket.htb/ --no-sign-request | jq

Таблицы в базе DynamoDB
Источник: xakep.ru


