Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124



Активную разведку проводят при пентесте, чтобы узнать максимум информации о цели. При этом допускается, что действия могут быть замечены — например, занесены в логи. На этом этапе мы соберем информацию о URL и эндпоинтах сервисов заказчика, определим используемые технологии — в общем, вытащим все, что поможет нам в продвижении.
Эта статья продолжает цикл, посвященный созданию идеального рабочего процесса. Эти статьи призваны помочь исследователям и техническим специалистам разобраться в последовательности действий, анализе результатов и выборе инструментов.
Дальше будем считать, что пассивную разведку мы уже завершили и у нас есть определенная информация о цели. Процесс я подробно описывал в прошлой статье, так что при дальнейшем обсуждении будем исходить из того, что у нас уже есть некоторые наработки.
Давай подумаем о предстоящих целях. На этом этапе наша задача сводится к следующему:
Итак, будем считать, что у нас уже есть огромный список уникальных URL и доменов, собранных пассивно. Чтобы эффективно с ними работать, нужно отсортировать их по статус‑кодам. Этот шаг я включил в этап Enum, потому что тут мы уже активно взаимодействуем с целевой инфраструктурой и это уже не относится к пассивным методам.
Пример команды:
cat uniq_passive_urls | httpx -mc 200,201,202,204,206,301,302,401,403,404,405,500,502,503 -o live_passive_url
Основные статус‑коды (на случай, если кто‑то позабыл):
Range; PUT, DELETE); Если у нас большой скоуп и список URL-адресов тоже впечатляюще велик, то надо использовать трюк с разбивкой на части.
Команда для разделения большого списка URL на части:
split -l 5000 ../uniq_passive_urls target_part_
Пример команды для поэтапного запуска:
( trap 'pkill -P $$' SIGINT; for file in target_part_*; do httpx -list "$file" -mc 200,201,202,204,206,301,302,401,403,404,405,500,502,503 -o "httpx-optimized_${file}.txt" & done; wait )
Команда для объединения нескольких файлов в один файл:
cat httpx-optimized_* | anew live_passive_url
Или оставь только самые важные статус‑коды, например 200, 301, 302, 500, 502 и 503. Ответы на коды 401 и 403 можно будет потом собрать отдельно.
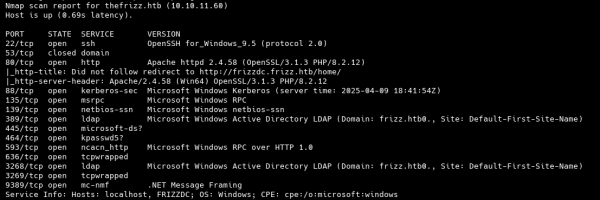
Утилита Naabu, думаю, всем знакома (если нет, у нее отличная документация). Здесь я покажу, как запустить сканирование в активном режиме.
Но сначала подготовим список для сканирования:
cat live_subdomains.txt ip_list_resolved | anew for_port_scan
Почему мы объединяем домены и IP? Это помогает обеспечить максимальное покрытие при анализе сканерами. Например, сканер может не обнаружить уязвимость по адресу http://1.1.1.1:9443, но найдет ее на http://example.com:9443. Или, если доступ к веб‑сервису через IP заблокирован, мы сможем просканировать его по домену. От нас никто не уйдет!
naabu -list for_port_scan -verify -ec -retries 1 -p 0-65535 -warm-up-time 0 -c 50 -nmap-cli "nmap -sV -oA nmap-out" -o open_ports.txt
Если скоуп большой, можем разбить задачу на части и сканировать в многопоточном режиме:
split -l 500 ../for_port_scan target_part_
Команда для запуска Naabu на отдельных частях списка IP-адресов:
( trap 'pkill -P $$' SIGINT; for file in target_part_*; do naabu -silent -list "$file" -verify -ec -retries 1 -p 0-65535 -warm-up-time 0 -c 50 -rate 500 -nmap-cli "nmap -sV -sC -oA nmap-out_${file}" -o "naabu-optimized_${file}.txt" & done; wait )
Сохрани всё в файл open_ports.txt:
cat optimized_* | anew open_ports.txt info
Если сканируемый скоуп велик, лучше сначала запустить Naabu и передать Nmap файл со списком портов open_ports.txt, чем пользоваться командами из примеров выше.
Берем список из файла open_ports.txt и передаем его утилите httpx. На выходе получаем файл web_services.txt с веб‑сервисами на разных портах.
cat open_ports.txt | httpx -o web_app.txt
Прежде чем двигаться дальше, разделим текущий список на два отдельных. Это позволит нам эффективно искать виртуальные хосты — как через привязку IP к доменам, так и с помощью брутфорса доменов для конкретного IP-адреса.
Команда для создания списка в формате ip:port:
grep -E '^https?://([0-9]{1,3}.){3}[0-9]{1,3}(:[0-9]+)?$' web_app.txt > web_app_ip.txt
Команда для формирования списка в формате domain:port:
grep -Ev '^https?://([0-9]{1,3}.){3}[0-9]{1,3}(:[0-9]+)?$' web_app.txt > web_app_domain.txt Важный нюанс
Утилита httpx заменяет порты 80 и 443 префиксами http:// и https:// соответственно, оставляя нестандартные порты, такие как 8083, без изменений.
Чтобы решить эту проблему, можно использовать на этом этапе httprobe, а затем повторить те же шаги.
Удаляем префиксы http:// и https://:
sed 's|https?://||' web_app.txt > web_app2
Составляем список доменов:
grep -Ev '^([0-9]{1,3}.){3}[0-9]{1,3}:[0-9]+$' web_app2 > web_app_domain.txt
Составляем список с IP-адресами:
grep -E '^([0-9]{1,3}.){3}[0-9]{1,3}:[0-9]+$' web_app2 > web_app_ip.txt
После этапа пассивной разведки у нас уже есть неплохой список собранных поддоменов, и теперь пора его обработать. Вот что мы собираемся сделать:
Допустим, что этот список резолвящихся поддоменов у нас уже есть, ведь мы решили считать, что этап пассивной разведки уже завершен.
Осталось собрать список поддоменов, которые не резолвятся.
Пример команды:
comm -23 <(sort subdomains | uniq) <(sort live_subdomains.txt | uniq) > not_resolv_subdomain.txt
Теперь, имея на руках два списка поддоменов, нужно собрать из них те, которые резолвятся через публичные списки поддоменов и имеют статусы 401, 403 и 404. Это делается для последующего брутфорса и поиска способов обхода авторизации. Команда ниже сохранит в два файла нужные адреса со статус‑кодами 401, 403 и 404 для брута.
cat live_subdomain.txt | httpx -mc 401,403 -o 401_403.txt cat live_subdomain.txt | httpx -mc 404 -o 404.txt
Возникает вопрос: зачем нам два файла, а не один? Все просто: файл со статус‑кодами 401 и 403 мы потом дополним и будем пробовать байпасы.
Итак, списки для байпаса у нас есть, теперь подготовим список для брутфорса.
cat 401_403.txt 404.txt | anew for_brute_dir.txt
Ты, возможно, запутался, и это нормально — процесс не из легких. Давай посмотрим, что у нас получилось:
resolv_subdomain.txt; not_resolv_subdomain.txt; responses_401_403.txt; responses_404.txt.
Если httpx вдруг чем‑то тебя не устраивает или ты сомневаешься в корректности его результатов (такое за ним уже замечали), то существуют альтернативы, которые можно использовать. Давай кратко рассмотрим доступные варианты.
Источник: xakep.ru